1. Heap
Heap itu adalah struktur data berbasis pohon khusus dimana pohon itu adalah pohon biner lengkap. Heap itu juga merupakan pohon yang isi dari root hingga leaf berurut dari index pada array.
contoh : kita memiliki array[] : {4 3 2 6 5}, maka kita akan memiliki pohon heap seperti :
4
/ \
3 2
/ \
6 5
Dari contoh itu kita dapat melihat bahwa setiap node dari heap tree tersebut itu sesuai urutannya dengan value dari index pada array yang kita miliki.
Heap juga memiliki tiga macam, yaitu min heap, max heap, dan min-max heap.
Saya hanya akan membahas min heap dan max heap saja, karena min-max heap itu jarang digunakan.
A. Min Heap
1. Insertion Dalam Min Heap
Min heap adalah heap yang data di parent atau root memiliki value yang lebih kecil dari childnya.
contoh : kita memiliki value dalam array[] : {7 4 3 8 2 6 5}
langkah pertama yang kita lakukan adalah memasukan semua value dalam array itu seperti contoh diatas saat saya menjelaskan tentang heap, yaitu masukan value kedalam tree sesuai dengan urutan indexnya.
7
/ \
4 3
/ \ / \
8 2 6 5
Setelah kita memasukkan value tersebut menjadi bentuk tree, sekanjutnya kita akan membandingkan child dengan parentnya. Jika value dari child lebih kecil dari parentnya maka akan kita swap.
7 2
/ \ / \
4 3 => 4 3
/ \ / \ / \ / \
8 2 6 5 8 7 6 5
Saya akan menjelaskan cara melakukan swapping heap untuk min heap dari tree tersebut.
- Kita akan bandingkan value 2 dan 4, karena yang lebih kecil adalah 2 maka kita akan swapping 2 dengan 4.
- Lalu, saat 2 sudah di posisi 4, kita akan bandingkan kembali 2 dengan 7, karena yang lebih kecil 2 maka kita akan melakukan swapping 2 dengan 7 sehingga kita mendapatkan value root baru yaitu 2.
- Dan yang terakhir, kita akan menukar 7 dengan 4 karena 4 lebih kecil kita akan melakukan swapping sehingga tree akan terbentuk seperti urutan yang sebelah kanan.
2. Deletion Dalam Min Heap
Untuk deletion kita memakai cara yang sama seperti Binary Search Tree. Saya akan langsung menjelaskan caranya. Anggap saja kita memiliki array yang sama seperti array saat insertion min heap yaitu, array[] : {7 4 3 8 2 6 5} tetapi saya akan mengambil tree yang sudah memenuhi syarat min heap.
2
/ \
4 3
/ \ / \
8 7 6 5
Dari tree tersebut, misalnya saya ingin mendelete value 2 yang terletak di root. Nah untuk menggantinya kita ambil dari value urutan terakhir di index array (lebih mudahnya lagi, value yang terakhir dimasukkan kedalam tree) yaitu 5.
5
/ \
4 3
/ \ /
8 7 6
Setelah digantikkan root pada tree akan menjadi 5. setelah itu kita akan melakukan teknik heapify untuk mengganti / swapping dengan child yang memiliki nilai terkecil yaitu 3.
3
/ \
4 5
/ \ /
8 7 6
Bentuk tree akan menjadi seperti ini.
B. Max Heap
1. Insertion Dalam Max Heap
Cara melakukan insertion dalam max heap sama seperti min heap, tetapi untuk swapping sedikit berbeda, pada min heap semua parent valuenya akan lebih kecil daripada child, pada max heap valuenya akan lebih besar dari pada childnya.
contoh : kita memiliki tree sebagai berikut
5
/ \
10 3
/ \ / \
7 4 6 8
Kita akan melakukan swapping yang sama seperti min heap, tetapi bedanya adalah parent harus lebih besar daripada childnya.
- Dari tree tersebut kita akan melakukan swapping 3 dengan 8 karena 8 merupakan anak terbesar dari 3.
- Setelah itu kita akan melakukan swapping 10 dengan 5 karena 10 merupakan anak terbesar dari 5.
- setelah ditukar, 5 akan kita tukar kembali dengan 7 karena valuenya lebih besar.
Setelah melakukan semua itu kita mendapatkan tree sebagai berikut.
10
/ \
7 8
/ \ / \
5 4 6 3
2. Deletion Dalam Max Heap
Untuk deletion dalam max heap pun sama seperti min heap. Untuk contoh treenya saya akan ambil dari tree max heap yang sudah sesuai dengan syarat tree max heap.
10
/ \
7 8
/ \ / \
5 4 6 3
Lalu saya ingin mendelete value 8. Kita hanya langsung mendelete 8 dan menggantikannya dengan 3 setelah itu kita akan melakukan heapify dengan 6 dan langsung mendapatkan tree sebagai berikut.
10
/ \
7 6
/ \ /
5 4 3
C. Min-Max Heap
Untuk mempelajari min-max heap, saya akan mencantumkan sumbernya disini agar kalian bisa pelajari sendiri.
Sumber :
2. Tries
Trie adalah struktur data pencarian informasi yang efisien. Menggunakan Trie, kompleksitas pencarian dapat dibawa ke batas optimal (panjang kunci). Jika kita menyimpan kunci dalam pohon pencarian biner, BST yang seimbang akan membutuhkan waktu yang proporsional dengan M * log N, di mana M adalah panjang string maksimum dan N adalah jumlah key dalam pohon. Dengan menggunakan Trie, kita dapat mencari key dalam waktu O (M). Namun penalti ada pada persyaratan penyimpanan Trie (Silakan merujuk Aplikasi Trie untuk detail lebih lanjut).
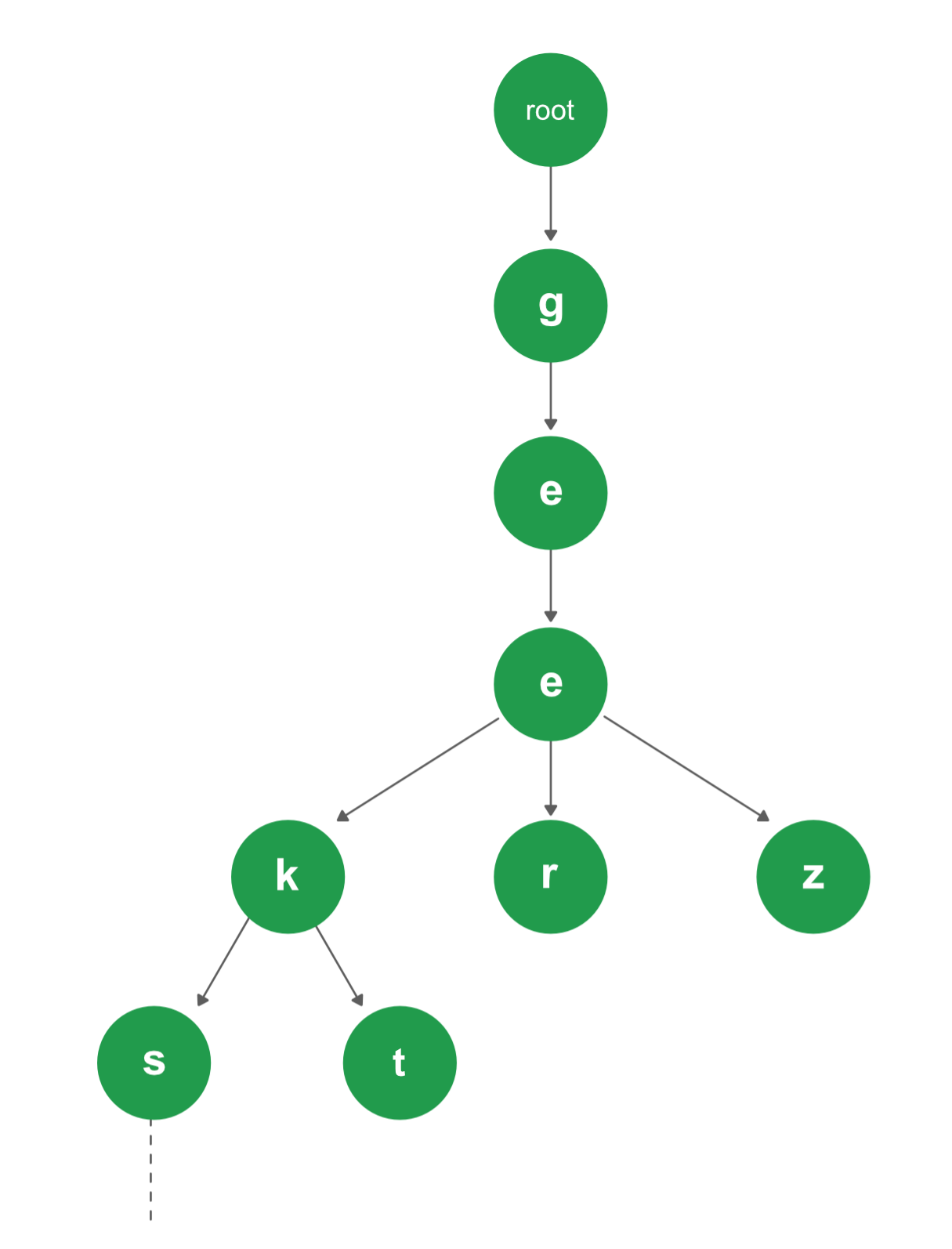
Setiap simpul Trie terdiri dari banyak cabang. Setiap cabang mewakili karakter kunci yang memungkinkan. Kita perlu menandai simpul terakhir dari setiap key sebagai simpul kata akhir. Bidang simpul Trie isEndOfWord digunakan untuk membedakan simpul tersebut sebagai simpul akhir kata. Struktur sederhana untuk mewakili simpul dari alfabet bahasa Inggris dapat sebagai berikut,
// Trie node
struct TrieNode
{
struct TrieNode *children[ALPHABET_SIZE]; // isEndOfWord is true if the node
// represents end of a word
bool isEndOfWord;
};
Memasukkan key ke Trie adalah pendekatan sederhana. Setiap karakter key input dimasukkan sebagai simpul Trie individual. Perhatikan bahwa anak-anak adalah array pointer (atau referensi) ke node trie level berikutnya. Karakter key bertindak sebagai indeks ke dalam array anak-anak. Jika kunci input adalah baru atau ekstensi dari kunci yang ada, kita perlu membangun simpul kunci yang tidak ada, dan menandai akhir kata untuk simpul terakhir. Jika key input adalah awalan dari key yang ada di Trie, kami cukup menandai simpul terakhir kunci sebagai akhir kata. Panjang key menentukan kedalaman Trie.
Mencari key mirip dengan memasukkan operasi, namun, kami hanya membandingkan karakter dan bergerak ke bawah. Pencarian dapat diakhiri karena akhir string atau kurangnya key dalam trie. Dalam kasus sebelumnya, jika bidang isEndofWord dari simpul terakhir benar, maka key ada di trie. Dalam kasus kedua, pencarian berakhir tanpa memeriksa semua karakter kunci, karena key tidak ada dalam trie.
Gambar berikut menjelaskan konstruksi trie menggunakan kunci yang diberikan dalam contoh di bawah ini,
root
/ \ \
t a b
| | |
h n y
| | \ |
e s y e
/ | |
i r w
| | |
r e e
|
r
Dalam gambar, setiap karakter bertipe trie_node_t. Sebagai contoh, root adalah tipe trie_node_t, dan itu anak-anak a, b dan t diisi, semua node root lainnya adalah NULL. Demikian pula, "a" di tingkat berikutnya hanya memiliki satu anak ("n"), semua anak lainnya adalah NULL. Node daun yang berwarna biru.
Sekian dari penjelasan saya mengenai Heap dan Tries. Semoga bermanfaat untuk kalian semua.
Nama : Reinhart Perbowo Pujo Leksono
NIM : 2301857254
Source:
- https://www.geeksforgeeks.org/heap-data-structure/
- https://practice.geeksforgeeks.org/problems/max-heap-and-min-heap
- https://medium.com/@randerson112358/min-heap-deletion-step-by-step-1e05ff9d3932
- https://www.geeksforgeeks.org/insertion-and-deletion-in-heaps/
- https://en.wikipedia.org/wiki/Min-max_heap
- https://www.geeksforgeeks.org/binary-heap/
- https://www.geeksforgeeks.org/trie-insert-and-search/